
Этот пост является Частью 4 из серии из четырёх частей. Обязательно ознакомься с другими постами в серии для более глубокого погружения в наш генератор бизнес-планов на базе ИИ.
Часть 1: Как мы создали генератор бизнес-планов на базе ИИ с использованием LangGraph & LangChain
Часть 2: Как мы оптимизировали генерацию бизнес-планов на базе ИИ: компромиссы скорости и качества
Часть 3: Как мы создали 273 модульных теста за 3 дня без написания единой строки кода
Часть 4: Фреймворк оценки ИИ — Как мы создали систему для оценки и улучшения бизнес-планов, созданных ИИ
Введение: Проблемы оценки бизнес-планов с ИИ
Объективная оценка контента, созданного искусственным интеллектом, является сложной. В отличие от структурированных результатов с чёткими правильными или неправильными ответами, бизнес-планы требуют стратегического мышления, оценки выполнимости и согласованности, что делает оценку высоко субъективной.
Это породило ключевые вызовы:
- Как мы определяем «хорошее» и «плохое» содержание бизнес-плана?
- Как мы можем обеспечить самосовершенствование ИИ со временем?
- Как сделать оценку последовательной и беспристрастной?
Чтобы решить эту задачу, мы разработали структурированную систему оценок, которая позволяет нам оценивать, корректировать и улучшать генерируемые ИИ бизнес-планы. Наш подход сочетает несколько систем оценки, каждая из которых адаптирована к различным разделам плана, что обеспечивает точность и стратегическую глубину.
Важно отметить, что эта детальная система оценки была частью нашей первоначальной реализации, где каждый раздел проходил тщательную оценку и итерацию. Однако из-за ограничений производительности мы упростили процесс оценки в MVP чтобы приоритизировать скорость генерации. Этот компромисс помог нам быстрее развернуться, сохраняя при этом рамки оценки как часть текущих исследований для будущих улучшений.
Недавние исследования в области оценки на основе LLM подтвердили эффективность структурированной оценки ИИ. Исследования, такие как Prometheus 2: Открытая языковая модель, специализирующаяся на оценке других языковых моделей (2024) и фреймворк Evals от OpenAI показали, что LLM могут быть надежными оценщиками, если они руководствуются структурированными критериями оценки.
Разработка Фреймворка Оценки
Мы вдохновились системами оценки учителей и применили это к бизнес-планам, созданным с помощью ИИ. Это привело к созданию нескольких оценочных систем, каждая из которых адаптирована для различных типов разделов.
Фреймворки Оценки по Типам Разделов
Вместо использования универсального метода оценки мы разработали индивидуальные критерии оценки в зависимости от типа анализируемого контента:
Стратегическое планирование и бизнес-модель
- Оценено на предмет ясности, соответствия SMART-целям и осуществимости.
- Требуются ясные планы действий и структурированное постановление целей.
Исследование рынка и анализ конкурентов
- Сосредоточен на глубине исследования, уникальности и проверке данных в реальных условиях.
- Ответы ИИ оценивались по реалистичности рынка и конкурентному позиционированию.
Финансовое планирование и прогнозы
- Оценка финансовых предположений, моделирование доходов и разбивка расходов.
- Результаты ИИ должны быть количественно оценены, внутренне согласованы и разумны.
Операционная и исполнительная стратегия
- Оценка по практичности, снижению рисков и дорожной карте реализации.
- Необходима четкая структура команды и распределение ресурсов.
Стратегия Маркетинга и Продаж
- Оценено на соответствие целевой аудитории, потенциал конверсии и согласованность брендинга.
- Маркетинговые планы, созданные с помощью ИИ, должны быть конкретными и основанными на данных.
Каждый фреймворк присваивал веса различным измерениям оценки, обеспечивая тем самым, чтобы критически важные области (например, финансовая жизнеспособность) влияли на общий балл больше, чем менее критические. Это согласуется с недавними результатами из Prometheus 2: Открытая модель языка, специализирующаяся на оценке других языковых моделей, которые подчеркивают необходимость детальных оценочных бенчмарков с использованием LLMs.
Механизм Оценки Результатов
Каждый раздел был оценен от 1 до 5, согласно критериям:

Итеративное улучшение на основе ИИ
Чтобы позволить ИИ самосовершенствоваться, мы разработали многоступенчатую систему обратной связи:
Шаг 1: Создание Черновика
- ИИ создаёт первоначальный черновик на основе ввода пользователя.
- Разделы структурированы в соответствии с предопределёнными шаблонами.
Шаг 2: Самооценка ИИ
- ИИ анализирует свои результаты с помощью специфических оценочных фреймворков для разделов.
- Выявляет области с отсутствующими данными, нечеткими объяснениями или слабой стратегической связью.
Шаг 3: Самосовершенствование ИИ
- ИИ восстанавливает слабые разделы, обеспечивая лучшее соответствие критериям оценки.
- Если финансовая или рыночная аналитика недостаточна, ИИ корректирует предположения и рассуждения.
Шаг 4: Финальная Оценка
- ИИ проводит второй проход оценки для подтверждения своих собственных улучшений.
- Окончательная версия сравнивается с предыдущими итерациями для отслеживания прогресса.
Этот итеративный процесс генерации → оценки → улучшения соответствует передовым исследованиям, показывающим, что оценки, основанные на LLM, улучшаются с каждым проходом.
Статистическая Валидация: Реально Ли Это Сработало?
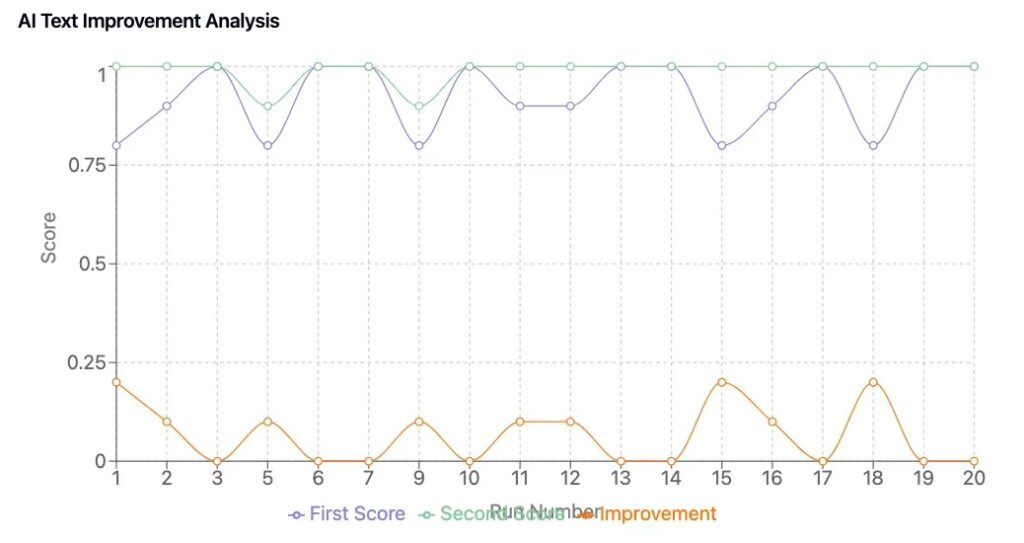
Чтобы подтвердить, что наша методика привела к ощутимым улучшениям, мы провели тестовый цикл из 50 планов, сравнивая бизнес-планы, сгенерированные с ИИ, с циклами самосовершенствования и без них.
Ключевые выводы
- Постоянство Оценок: Контент, сгенерированный ИИ, оценивается последовательно, сокращая случайные колебания в качестве планов.
- Измеримое Улучшение: Планы, которые прошли усовершенствование с помощью ИИ, улучшились в среднем на 0.6 до 1.2 баллов.
- Лучшие Бизнес-Выводы: Усовершенствованные версии имели более сильное стратегическое соответствие, более четкие финансовые прогнозы и более убедительные сообщения.
Эти результаты отражают тенденции, наблюдаемые в исследовании оценки LLM, где структурированные системы оценки и итеративное оценивание значительно улучшают контент, созданный ИИ.
Основные Выводы
1. ИИ Может Самосовершенствоваться При Наличии Структурированных Критериев Оценки
- Хорошо определённый фреймворк оценки позволяет ИИ распознавать и исправлять свои собственные слабости.
2. Количественная Оценка Обеспечивает Объективную Валидацию Контента
- Субъективная оценка была минимизирована с помощью стандартизированных критериев оценивания.
3. Методология Оценки Была Разработана Для Продвинутых Итераций ИИ, Но MVP Сосредоточилась На Скорости
- Первоначальная реализация включала несколько циклов оценки для каждого раздела.
- Из-за ограничений производительности мы упростили это в MVP, но сохранили для будущих исследований и улучшений.
4. Оценщики LLM — Общепромышленная Тенденция
- Новые модели оценки ИИ (например, Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, LLMs-as-Judges) повышают консистентность и снижают предвзятость. (arxiv.org)
- Область оценки ИИ развивается в сторону многоуровневых систем оценки, подтверждая подход, который мы первыми предложили.
Попробуй Наш Бизнес-Пакет на Базе ИИ
Мы разработали и оптимизировали наш генератор бизнес-планов на базе ИИ в DreamHost, обеспечивая уровень производительности и масштабируемости предприятия.
Клиенты DreamHost могут кликнуть здесь, чтобы начать и изучить наш генератор бизнес-планов на базе ИИ и другие инструменты ИИ.
Этот пост является Частью 4 из серии из 4 частей. Обязательно ознакомься с другими постами в серии для более глубокого погружения в наш генератор бизнес-планов с ИИ.
Часть 1: Как мы создали генератор бизнес-планов с ИИ, используя LangGraph & LangChain
Часть 2: Как мы оптимизировали генерацию бизнес-планов с ИИ: скорость против качества
Часть 3: Как мы создали 273 юнит-теста за 3 дня без написания единой строки кода
Часть 4: Рамки оценки ИИ — Как мы создали систему для оценки и улучшения бизнес-планов, созданных ИИ