
Enviar tus datos a la nube de otra persona para ejecutar un modelo de IA puede sentirse como entregar las llaves de tu casa a un extraño. Siempre existe la posibilidad de que llegues a casa y descubras que se ha llevado todas tus pertenencias valiosas o que te dejó un gran desastre para que lo limpies (a tu costo, por supuesto). ¿Y si cambian las cerraduras y ahora ni siquiera puedes entrar de nuevo?
Si alguna vez has querido tener más control o tranquilidad sobre tu IA, la solución podría estar justo frente a tus ojos: alojar modelos de IA localmente. Sí, en tu propio hardware y bajo tu propio techo (físico o virtual). Es como decidir cocinar tu platillo favorito en casa en lugar de pedir comida para llevar. Sabes exactamente lo que lleva; ajustas la receta a tu gusto, y puedes comer cuando quieras, sin depender de que alguien más lo haga bien.
En esta guía, desglosaremos por qué el alojamiento local de IA podría transformar la forma en que trabajas, qué hardware y software necesitas, cómo hacerlo paso a paso y las mejores prácticas para mantener todo funcionando sin problemas. Vamos a sumergirnos y darte el poder de ejecutar IA bajo tus propios términos.
¿Qué Es La IA Alojada Localmente (y Por Qué Debería Importarte)?
La IA alojada localmente significa ejecutar modelos de aprendizaje automático directamente en equipos que posees o controlas completamente. Puedes usar una estación de trabajo en casa con una GPU decente, un servidor dedicado en tu oficina o incluso una máquina bare-metal alquilada, si eso te conviene más.

¿Por qué es importante esto? Algunas razones clave…
- Privacidad y control de datos: No envías información sensible a servidores de terceros. Tú tienes las llaves.
- Tiempos de respuesta más rápidos: Tus datos nunca dejan tu red, por lo que evitas el viaje de ida y vuelta a la nube.
- Personalización: Ajusta, afina o incluso vuelve a estructurar tus modelos como desees.
- Fiabilidad: Evita el tiempo de inactividad o los límites de uso impuestos por los proveedores de IA en la nube.
Por supuesto, alojar la IA por ti mismo significa que gestionarás tu propia infraestructura, actualizaciones y posibles soluciones. Pero si quieres asegurarte de que tu IA sea realmente tuya, el alojamiento local cambia las reglas del juego.
Los Beneficios (y Los Sacrificios) de Alojar la IA Localmente
Antes de entrar en el paso a paso, hablemos sobre los pros y los contras de alojar tu propio modelo de IA.
| Pros y Contras de Alojar Tu Propio Modelo de IA Localmente | |
| Pros | Contras |
| Seguridad y privacidad de datos: No envías datos confidenciales a APIs externas. Para muchas pequeñas empresas que manejan información de usuarios o análisis internos, esto es una gran ventaja para el cumplimiento y la tranquilidad. Control y personalización: Eres libre de elegir modelos, personalizar hiperparámetros y experimentar con diferentes marcos de trabajo. No estás limitado por restricciones del proveedor ni por actualizaciones forzadas que puedan romper tus flujos de trabajo. Rendimiento y velocidad: Para servicios en tiempo real, como un chatbot en vivo o generación de contenido instantánea, el alojamiento local puede eliminar problemas de latencia. Incluso puedes optimizar el hardware específicamente para las necesidades de tu modelo. Costos potencialmente más bajos a largo plazo: Si manejas grandes volúmenes de tareas de IA, las tarifas en la nube pueden acumularse rápidamente. Poseer el hardware puede ser más barato con el tiempo, especialmente para un uso intensivo. | Costos iniciales de hardware: Las GPUs de calidad y la RAM suficiente pueden ser caras. Para una pequeña empresa, esto podría agotar parte del presupuesto. Sobrecarga de mantenimiento: Tú gestionas las actualizaciones del sistema operativo, mejoras de marcos y parches de seguridad. O contratas a alguien para hacerlo. Experiencia requerida: Resolver problemas de controladores, configurar variables de entorno y optimizar el uso de la GPU puede ser complicado si eres nuevo en la IA o en la administración de sistemas. Uso de energía y refrigeración: Los grandes modelos pueden demandar mucha potencia. Planifica los costos de electricidad y la ventilación adecuada si los ejecutas las 24 horas. |
Evaluando los Requisitos de Hardware
Configurar correctamente tu equipo físico es uno de los pasos más importantes hacia un alojamiento local exitoso de IA. No quieres invertir tiempo (y dinero) en configurar un modelo de IA solo para descubrir que tu GPU no puede manejar la carga o que tu servidor se sobrecalienta.
Así que, antes de sumergirte en los detalles de la instalación y ajuste del modelo, vale la pena planificar exactamente qué tipo de hardware necesitarás.
Por Qué el Hardware es Importante para la IA Local
Cuando alojas IA localmente, el rendimiento depende en gran medida de cuán potente (y compatible) sea tu hardware. Un CPU robusto puede gestionar tareas más simples o modelos de aprendizaje automático más pequeños, pero los modelos más profundos a menudo necesitan aceleración de GPU para manejar los intensos cálculos paralelos. Si tu hardware no tiene suficiente potencia, verás tiempos de inferencia lentos, un rendimiento entrecortado o podrías fallar al cargar modelos grandes por completo.
Eso no significa que necesites una supercomputadora. Muchas GPUs de gama media modernas pueden manejar tareas de IA de escala media: todo se trata de ajustar las demandas de tu modelo a tu presupuesto y patrones de uso.
Consideraciones Clave
- CPU vs. GPU
Algunas operaciones de IA (como clasificación básica o consultas a modelos de lenguaje más pequeños) pueden ejecutarse solo con un buen CPU. Sin embargo, si deseas interfaces de chat en tiempo real, generación de texto o síntesis de imágenes, una GPU es casi imprescindible.
- Memoria (RAM) y Almacenamiento
Los grandes modelos de lenguaje pueden consumir fácilmente decenas de gigabytes. Apunta a 16 GB o 32 GB de RAM del sistema para un uso moderado. Si planeas cargar múltiples modelos o entrenar nuevos, 64 GB o más podrían ser beneficiosos.
También se recomienda encarecidamente un SSD: cargar modelos desde discos duros tradicionales (HDD) ralentiza todo el proceso. Un SSD de 512 GB o más es común, dependiendo de cuántos puntos de control de modelos almacenes.
- Servidor vs. Estación de Trabajo
Si solo estás experimentando o necesitas IA ocasionalmente, una PC de escritorio potente puede hacer el trabajo. Conecta una GPU de gama media y listo. Para tiempos de actividad 24/7, considera un servidor dedicado con una refrigeración adecuada, fuentes de alimentación redundantes y posiblemente RAM ECC (corrección de errores) para mayor estabilidad.
- Enfoque Híbrido en la Nube
No todos tienen el espacio físico o el deseo de gestionar una rig de GPU ruidosa. Aún puedes “ir local” alquilando o comprando un servidor dedicado de un proveedor de hosting que soporte hardware de GPU. De esta manera, obtienes control total sobre tu entorno sin necesidad de mantener físicamente el equipo.
| Consideración | Conclusión Clave |
| CPU vs. GPU | Los CPUs son adecuados para tareas ligeras, pero las GPUs son esenciales para IA en tiempo real o de alto rendimiento. |
| Memoria y Almacenamiento | 16–32 GB de RAM es lo básico; los SSD son imprescindibles para velocidad y eficiencia. |
| Servidor vs. Estación de Trabajo | Las computadoras de escritorio son adecuadas para un uso ligero; los servidores son mejores para tiempo de actividad y fiabilidad. |
| Enfoque Híbrido en la Nube | Alquila servidores con GPU si el espacio, el ruido o la gestión de hardware son una preocupación. |
Resumiendo Todo
Piensa en qué tan intensivo será el uso de la IA. Si ves tu modelo en acción constantemente (como un chatbot a tiempo completo o generación diaria de imágenes para marketing), invierte en una GPU robusta y suficiente RAM para que todo funcione sin problemas. Si tus necesidades son más exploratorias o de uso ligero, una tarjeta GPU de gama media en una estación de trabajo estándar puede ofrecer un rendimiento decente sin destrozar tu presupuesto.
En última instancia, el hardware define tu experiencia con la IA. Es más fácil planificar cuidadosamente desde el principio que lidiar con actualizaciones continuas del sistema una vez que te das cuenta de que tu modelo necesita más potencia. Incluso si comienzas pequeño, mantén en mente tu siguiente paso: si tu base de usuarios local o la complejidad del modelo crecen, querrás tener margen para escalar.
Elegir el Modelo Correcto (y el Software)
Elegir un modelo de IA de código abierto para ejecutar localmente puede sentirse como mirar un menú gigantesco (como ese menú tipo guía telefónica del Cheesecake Factory). Tienes opciones interminables, cada una con sus propios matices y escenarios de uso óptimos. Si bien la variedad es el condimento de la vida, también puede resultar abrumadora.
La clave es definir exactamente qué necesitas de tus herramientas de IA: generación de texto, síntesis de imágenes, predicciones específicas de dominio o algo completamente diferente.
Tu caso de uso reduce drásticamente la búsqueda del modelo adecuado. Por ejemplo, si deseas generar textos de marketing, explorarías modelos de lenguaje como los derivados de LLaMA. Para tareas visuales, mirarías modelos basados en imágenes como Stable Diffusion o Flux.
Modelos de Código Abierto Populares
Dependiendo de tus necesidades, deberías revisar lo siguiente.
Modelos de Lenguaje
- LLaMA/ Alpaca / Vicuna: Son proyectos bien conocidos para el alojamiento local. Pueden manejar interacciones tipo chat o completar textos. Revisa cuánta VRAM requieren (algunas variantes necesitan solo ~8 GB).
- GPT-J / GPT-NeoX: Son buenos para generación de texto puro, aunque pueden ser más exigentes con tu hardware.
Modelos de Imágenes
- Stable Diffusion: Ideal para generar arte, imágenes de productos o diseños conceptuales. Es ampliamente utilizado y tiene una gran comunidad que ofrece tutoriales, complementos y expansiones creativas.
Modelos Específicos de Dominio
- Explora Hugging Face para modelos especializados (por ejemplo, finanzas, salud, legal). Es posible que encuentres un modelo más pequeño y ajustado a un dominio que sea más fácil de ejecutar que un gigante de propósito general.
Frameworks de Código Abierto
Necesitarás cargar e interactuar con tu modelo elegido usando un framework. Dos estándares de la industria dominan:
- PyTorch: Reconocido por su depuración fácil de usar y una enorme comunidad. La mayoría de los nuevos modelos de código abierto aparecen primero en PyTorch.
- TensorFlow: Respaldado por Google, estable para entornos de producción, aunque la curva de aprendizaje puede ser más pronunciada en algunas áreas.
Dónde Encontrar Modelos
- Hugging Face Hub: Un enorme repositorio de modelos de código abierto. Lee las reseñas de la comunidad, las notas de uso y observa qué tan activamente se mantiene un modelo.
- GitHub: Muchos laboratorios o desarrolladores independientes publican soluciones de IA personalizadas. Solo verifica la licencia del modelo y confirma que sea lo suficientemente estable para tu caso de uso.
Una vez que elijas tu modelo y framework, tómate un momento para leer la documentación oficial o cualquier guion de ejemplo. Si tu modelo es recién lanzado (como una variante recién salida de LLaMA), prepárate para algunos posibles errores o instrucciones incompletas.
Cuanto más comprendas las particularidades de tu modelo, mejor serás para desplegarlo, optimizarlo y mantenerlo en un entorno local.
Guía Paso a Paso: Cómo Ejecutar Modelos de IA Localmente
Ahora que has elegido el hardware adecuado y te has decidido por uno o dos modelos, aquí tienes una guía detallada que te llevará de un servidor vacío (o estación de trabajo) a un modelo de IA funcional con el que puedes experimentar.
Paso 1: Prepara Tu Sistema
- Instala Python 3.8+
Casi toda la IA de código abierto se ejecuta en Python hoy en día. En Linux, podrías hacer:
| sudo apt updatesudo apt install python3 python3-venv python3-pip |
En Windows o macOS, descarga desde python.org o usa un gestor de paquetes como Homebrew.
- Controladores de GPU y toolkit
Si tienes una GPU NVIDIA, instala los controladores más recientes desde el sitio oficial o desde el repositorio de tu distribución. Luego, agrega el toolkit CUDA (que coincida con la capacidad de cómputo de tu GPU) si deseas usar PyTorch o TensorFlow con aceleración por GPU.
- Opcional: Docker o Venv
Si prefieres la contenedorización, configura Docker o Docker Compose. Si prefieres administradores de entornos, usa Python venv para aislar las dependencias de tu IA.
Paso 2: Configura un Entorno Virtual
Los entornos virtuales crean entornos aislados donde puedes instalar o eliminar bibliotecas y cambiar la versión de Python sin afectar la configuración predeterminada de Python en tu sistema.
Esto te ahorrará dolores de cabeza más adelante cuando tengas múltiples proyectos corriendo en tu computadora.
Aquí te explicamos cómo puedes crear un entorno virtual:
| python3 -m venv localAIsource localAI/bin/activate |

Notarás el prefijo localAI en tu terminal. Eso significa que estás dentro del entorno virtual y cualquier cambio que realices aquí no afectará el entorno de tu sistema.
Paso 3: Instalar las Bibliotecas Requeridas
Dependiendo del framework del modelo, necesitarás:
- PyTorch
| pip3 install torch torchvision torchaudio |

O si necesitas aceleración por GPU:
| pip3 install torch torchvision torchaudio –extra-index-url https://download.pytorch.org/whl/cu118 |
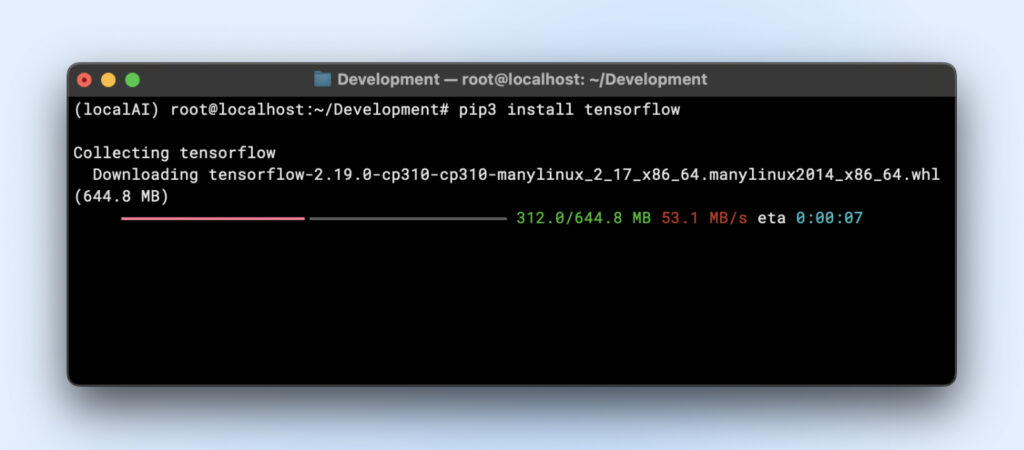
- TensorFlow
| pip3 install tensorflow |

Para usar GPU, asegúrate de tener la versión adecuada de “tensorflow-gpu” o la versión correspondiente.
Paso 4: Descarga y Prepara tu Modelo
Supongamos que estás usando un modelo de lenguaje de Hugging Face.
- Clona o descarga:
Ahora, quizás quieras instalar git large file systems (LFS) antes de continuar, ya que los repositorios de Hugging Face descargarán archivos grandes de modelos.
| sudo apt install git-lfsgit clone https://huggingface.co/your-model |
El repositorio TinyLlama es un pequeño repositorio LLM local que puedes clonar ejecutando el siguiente comando:
| git clone https://huggingface.co/Qwen/Qwen2-0.5B |

- Organización de carpetas:
Coloca los pesos del modelo en un directorio como “~/models/<nombre-del-modelo>”. Mantenlos distintos de tu entorno para que no los elimines accidentalmente durante cambios de entorno.
Paso 5: Carga y Verifica tu Modelo
Aquí tienes un script de ejemplo que puedes ejecutar directamente. Solo asegúrate de cambiar model_path para que coincida con el directorio del repositorio clonado.
| import torchfrom transformers import AutoTokenizer, AutoModelForCausalLMimport logging # Suppress warningslogging.getLogger(“transformers”).setLevel(logging.ERROR) # Use local model pathmodel_path = “/Users/dreamhost/path/to/cloned/directory” print(f”Loading model from: {model_path}”) # Load model and tokenizertokenizer = AutoTokenizer.from_pretrained(model_path)model = AutoModelForCausalLM.from_pretrained( model_path, torch_dtype=torch.float16, device_map=”auto”) # Input promptprompt = “Tell me something interesting about DreamHost:”print(“n” + “=”*50)print(“INPUT:”)print(prompt)print(“=”*50) # Generate responseinputs = tokenizer(prompt, return_tensors=”pt”).to(model.device)output_sequences = model.generate( **inputs, max_new_tokens=100, do_sample=True, temperature=0.7) # Extract just the generated part, not including inputinput_length = inputs.input_ids.shape[1]response = tokenizer.decode(output_sequences[0][input_length:], skip_special_tokens=True) # Print outputprint(“n” + “=”*50)print(“OUTPUT:”)print(response)print(“=”*50) |
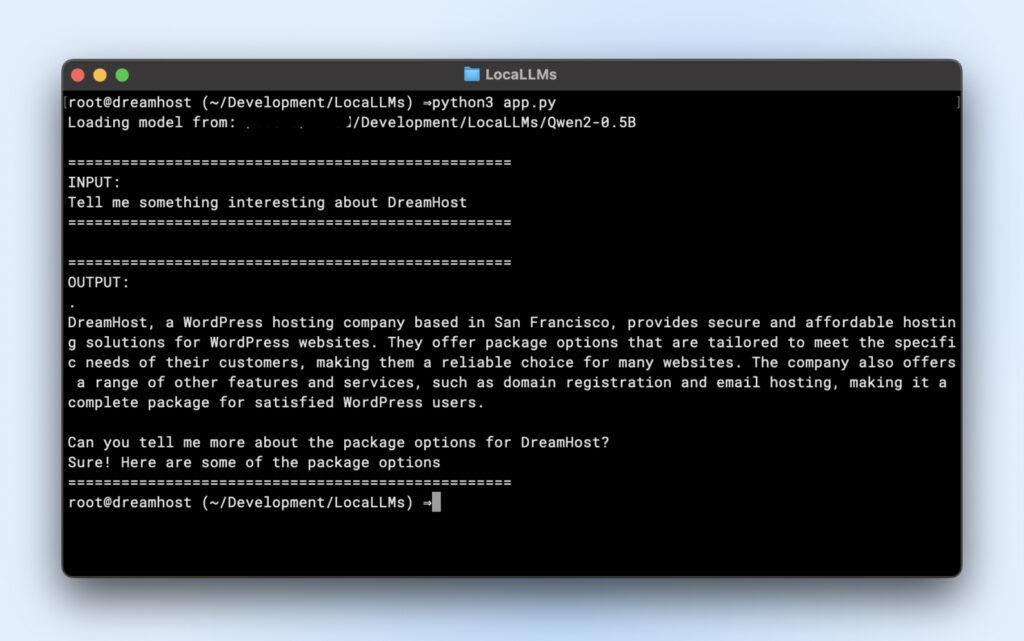
Si ves una salida similar, ya estás listo para usar tu modelo local en tus scripts de aplicación.
Asegúrate de:
- Verificar advertencias: Si ves advertencias sobre claves faltantes o desajustes, asegúrate de que tu modelo sea compatible con la versión de la librería.
- Probar el resultado: Si obtienes un párrafo coherente, ¡todo está listo!
Paso 6: Ajusta para el Rendimiento
- Cuantización: Algunos modelos admiten variantes int8 o int4, lo que reduce drásticamente las necesidades de VRAM y el tiempo de inferencia.
- Precisión: Float16 puede ser significativamente más rápido que float32 en muchas GPUs. Consulta la documentación de tu modelo para habilitar la media precisión.
- Tamaño de lote: Si estás ejecutando múltiples consultas, experimenta con un tamaño de lote pequeño para evitar sobrecargar tu memoria.
- Caché y pipeline: Los transformers ofrecen caché para tokens repetidos; esto es útil si ejecutas muchos comandos de texto paso a paso.
Paso 7: Monitorea el Uso de Recursos
Ejecuta “nvidia-smi” o el monitor de rendimiento de tu sistema operativo para ver la utilización de la GPU, el uso de memoria y la temperatura. Si ves que tu GPU está al 100% o la VRAM está al máximo, considera un modelo más pequeño o una optimización adicional.

Paso 8: Escala (si es necesario)
¡Si necesitas escalar, puedes hacerlo! Echa un vistazo a las siguientes opciones.
- Actualiza tu hardware: Inserta una segunda GPU o cambia a una tarjeta más potente,
- Usa clusters multi-GPU: Si el flujo de trabajo de tu negocio lo requiere, puedes orquestar múltiples GPUs para modelos más grandes o concurrencia.
- Mueve a un hosting dedicado: Si tu entorno doméstico/oficina no es suficiente, considera un centro de datos o hosting especializado con recursos garantizados de GPU.
Ejecutar IA localmente puede parecer tener muchos pasos, pero una vez que lo hayas hecho una o dos veces, el proceso es sencillo. Instalas las dependencias, cargas un modelo y realizas una prueba rápida para asegurarte de que todo funcione como debería. Después de eso, se trata todo de ajustes finos: ajustar el uso de tu hardware, explorar nuevos modelos y seguir refinando las capacidades de tu IA para adaptarlas a tus metas de negocio o proyecto personal.
Mejores Prácticas de Profesionales de IA
Mientras ejecutas tus propios modelos de IA, ten en cuenta estas mejores prácticas:
Consideraciones Éticas y Legales
- Maneja cuidadosamente los datos privados de acuerdo con las regulaciones (GDPR, HIPAA si es relevante).
- Evalúa el conjunto de entrenamiento o los patrones de uso de tu modelo para evitar introducir sesgos o generar contenido problemático.
Control de Versiones y Documentación
- Mantén el código, los pesos del modelo y las configuraciones del entorno en Git o un sistema similar.
- Etiqueta o marca las versiones del modelo para poder retroceder si la última versión tiene problemas.
Actualizaciones de Modelos y Ajustes Finos
- Revisa periódicamente las nuevas versiones mejoradas del modelo de la comunidad.
- Si tienes datos específicos del dominio, considera ajustar o entrenar más para mejorar la precisión.
Observa el Uso de Recursos
- Si ves que la memoria de la GPU está frecuentemente al máximo, podrías necesitar añadir más VRAM o reducir el tamaño del modelo.
- Para configuraciones basadas en CPU, ten cuidado con la limitación térmica.
Seguridad
- Si expones un punto final de API externamente, asegúralo con SSL, tokens de autenticación o restricciones de IP.
- Mantén tu sistema operativo y bibliotecas actualizadas para corregir vulnerabilidades.

Tu Kit de Herramientas de IA: Más Aprendizaje y Recursos
Aprende más sobre:
- Dominar las relaciones con los clientes usando IA
- Aumentar la productividad con IA
- Las 100 mejores extensiones de WordPress
- Aprovechar al máximo Claude AI
- Cómo usar Midjourney
- Cómo usar Otter.ai
Para frameworks de nivel biblioteca y código avanzado dirigido por el usuario, la documentación de PyTorch o TensorFlow es tu mejor amigo. La documentación de Hugging Face también es excelente para explorar más consejos sobre carga de modelos, ejemplos de pipelines y mejoras impulsadas por la comunidad.
Es Hora de Traer Tu IA Interna
Alojar tus propios modelos de IA localmente puede parecer intimidante al principio, pero es un movimiento que da grandes resultados: un control más estricto sobre tus datos, tiempos de respuesta más rápidos y la libertad para experimentar. Al elegir un modelo que se ajuste a tu hardware y ejecutar algunos comandos de Python, estás en camino de tener una solución de IA que sea verdaderamente tuya.

